
北京智源人工智能研究院发布了一款名为Emu3的多模态世界模型,这款模型以其原生多模态能力和统一输入输出的特性著称。
简单来说就是文,图,视频理解一站式模型,我们来看看。 Emu3的主要功能
图像生成
只需一段文本描述,Emu3就能生成高质量图像,支持不同分辨率和风格。

实测画面质量与Midjourney V5.1差不多,中规中矩。
视频生成
Emu3能生成视频,通过预测视频序列中的下一个符号来创作视频,不依赖复杂的视频扩散技术。


视频预测
Emu3能自然地延续现有视频内容,预测接下来会发生什么,模拟物理世界中的环境、人物和动物。

简单来说就是给她一段视频,它能够预测视频中物体的**轨迹来继续生成后续内容。

图文理解
Emu3能理解物理世界并提供连贯的文本回应,无需依赖CLIP或预训练的语言模型。

基本的图片理解
这张图片是一本名为“Parktakes”的杂志的封面,该杂志是 2017 年秋季刊。封面上有两个人坐在白色皮划艇上,在水面上划桨。皮划艇呈对角线位置,两个人坐在前面。两人都穿着红色带黑色带子的救生衣,他们拿着带有橙色刀片的桨。左边的人是一位留着黑色长发的女人,戴着墨镜,穿着黑色上衣。右边的人是一个短发男子,穿着绿色衬衫,戴着浅色的帽子。他们俩似乎都面带微笑,享受着在水上的时光。背景显示了树木和绿色植物的自然环境,表明它们可能位于公园或自然保护区中。水面平静,看不到天空,营造出宁静祥和的环境。
图像搜索

该图像展示了布鲁克林大桥,这是纽约市著名的悬索桥,以其独特的塔楼和支撑它的电缆网而闻名。这座标志性的建筑连接着布鲁克林和曼哈顿的行政区。 技术原理
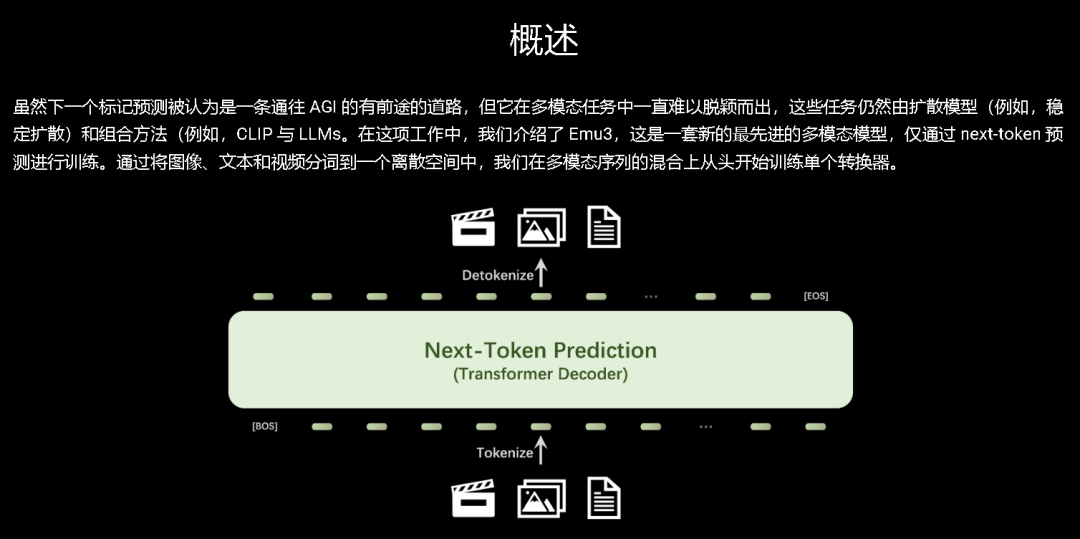
Emu3的核心是Next token预测,属于一种自回归方法,模型被训练预测序列中的下一个元素,无论是文本、图像还是视频。
Emu3将图像、文本和视频数据统一到一个离散的token空间中,使单一的Transformer模型处理多种类型的数据。
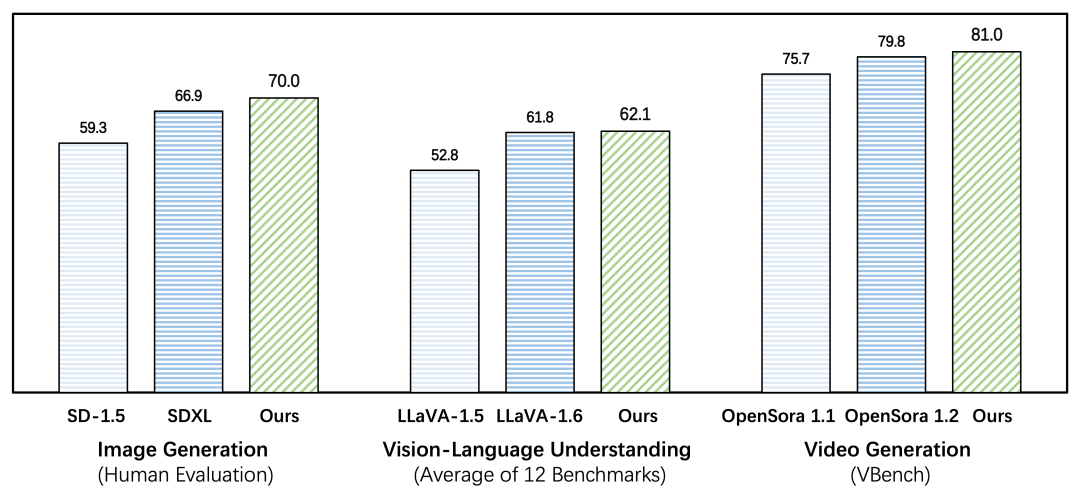
它超越了 SDXL、LLaVA-1.6 和 OpenSora-1.2 等旗舰开放模型,同时消除了对扩散或组合架构的需求。
项目官网:https://emu.baai.ac.cn/
今天的文章就到这里。
编辑丨惊云
审核丨核桃丨可乐
部分图片素材来源于网络,侵删

 美国
美国 加拿大
加拿大 新加坡
新加坡 日本
日本 迪拜
迪拜 澳洲
澳洲 泰国
泰国 越南
越南 新西兰
新西兰 马来
马来 意大利
意大利 英国
英国 德国
德国 法国
法国 西班牙
西班牙





